Executive Summary
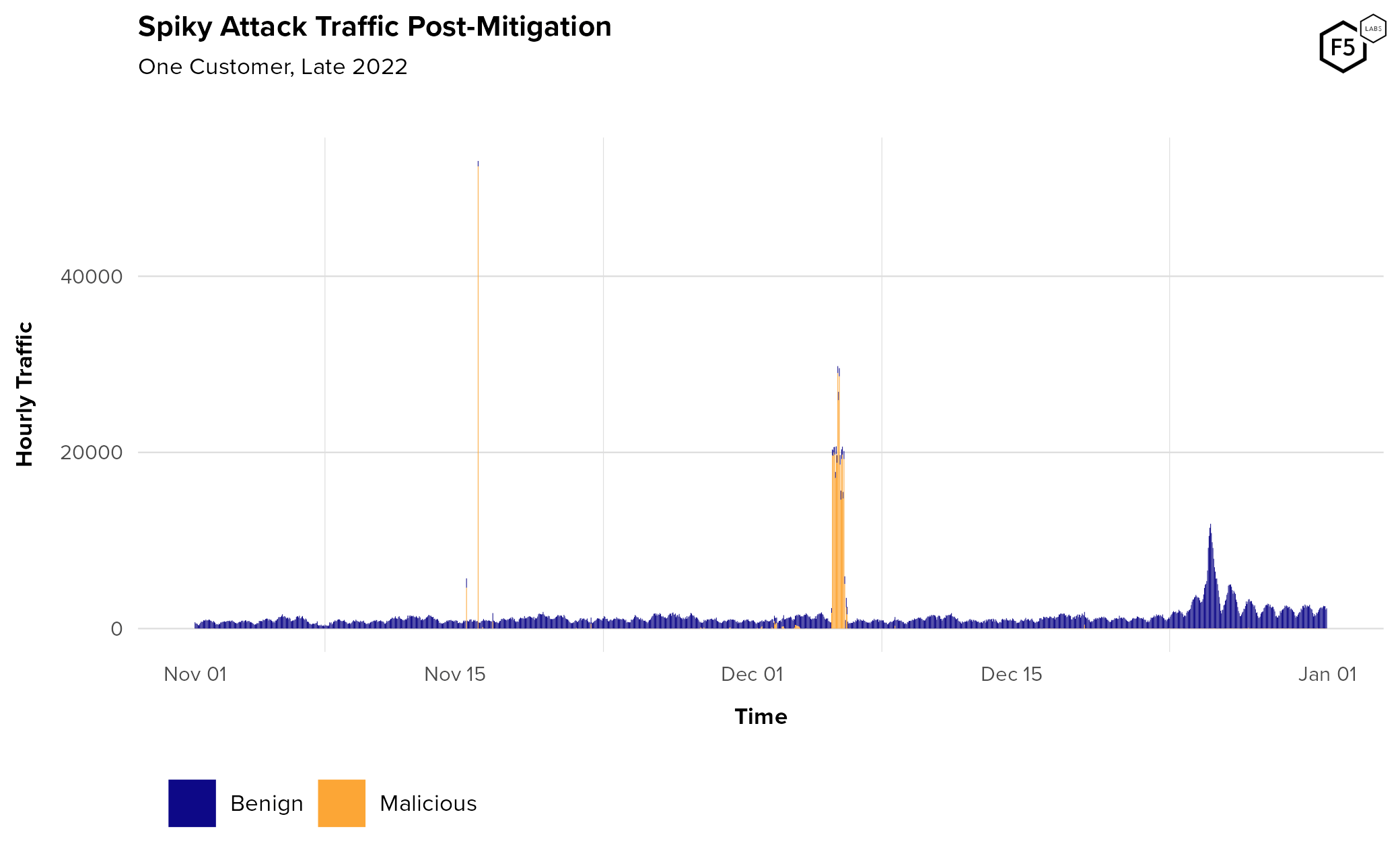
- Threats to digital identities are continuous in nature, widespread in targeting, and progressive in their evolution.
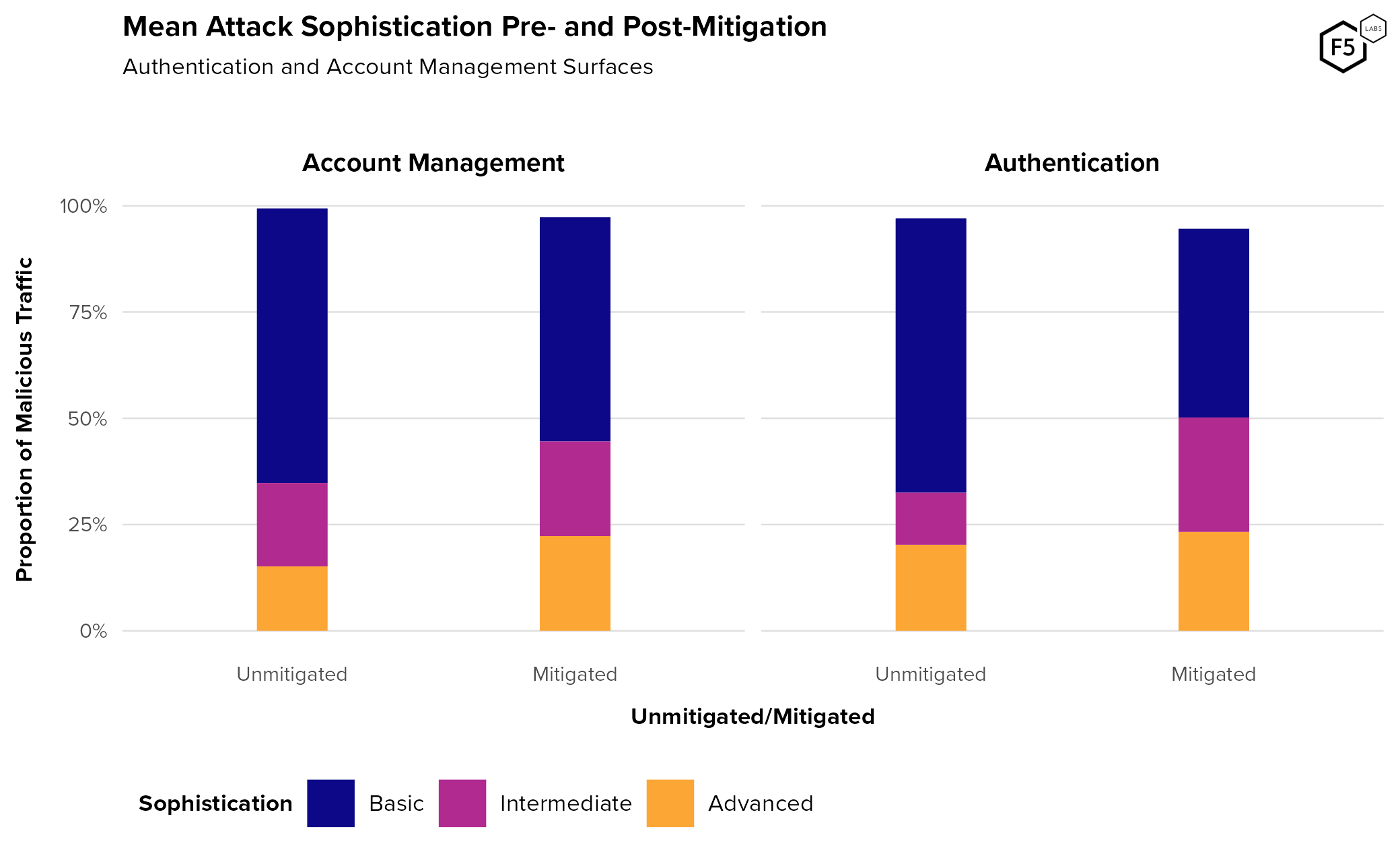
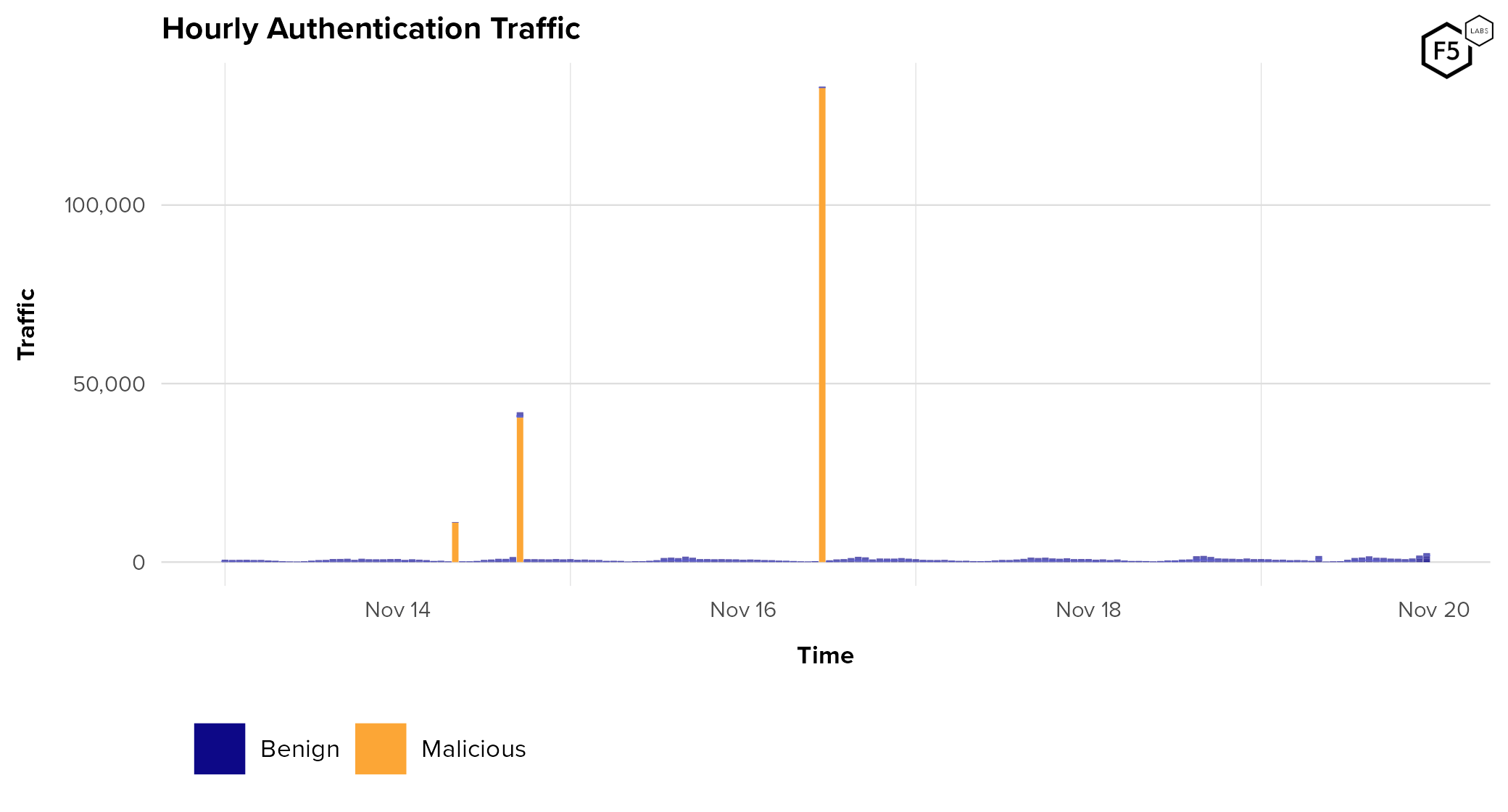
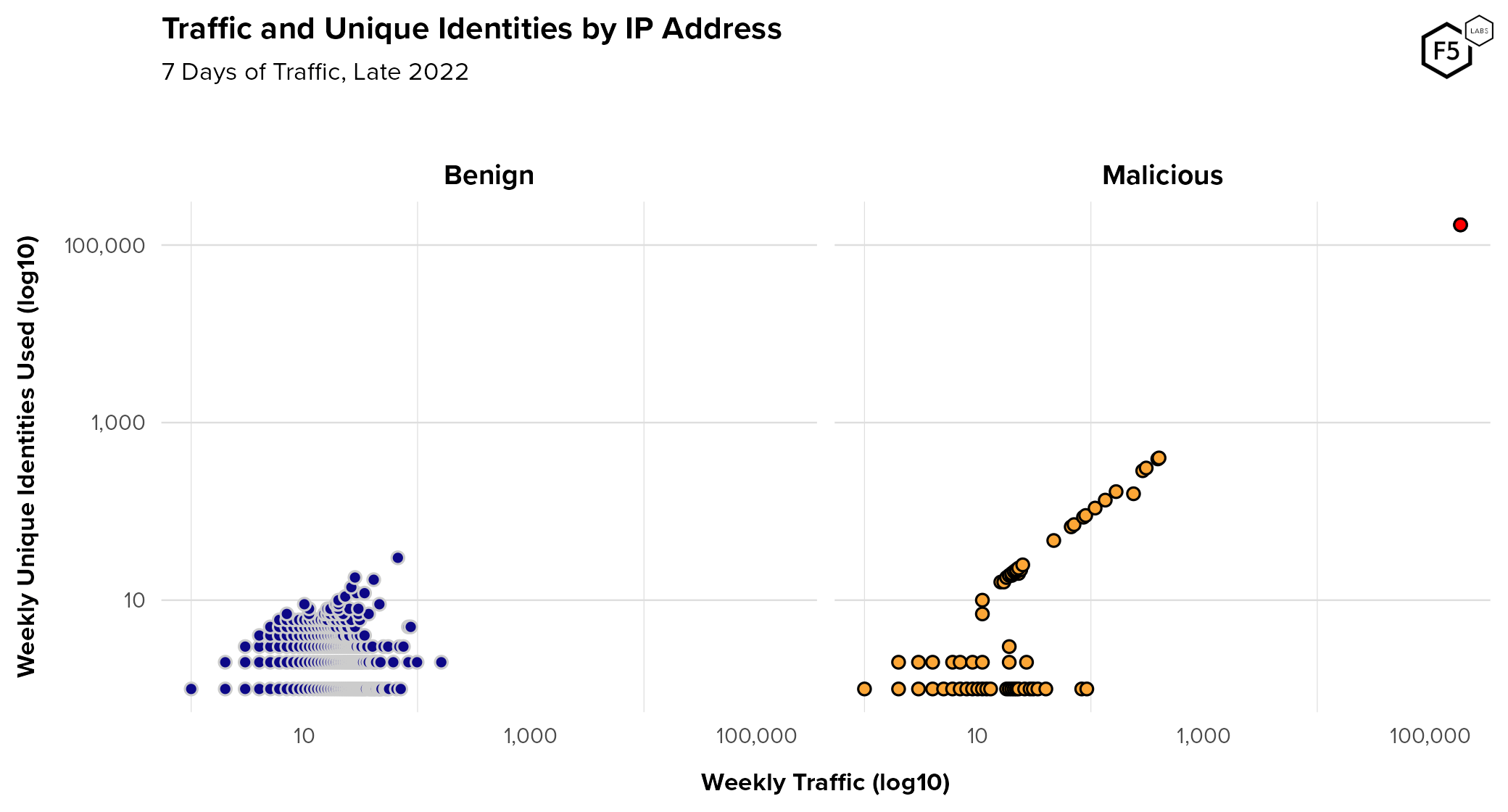
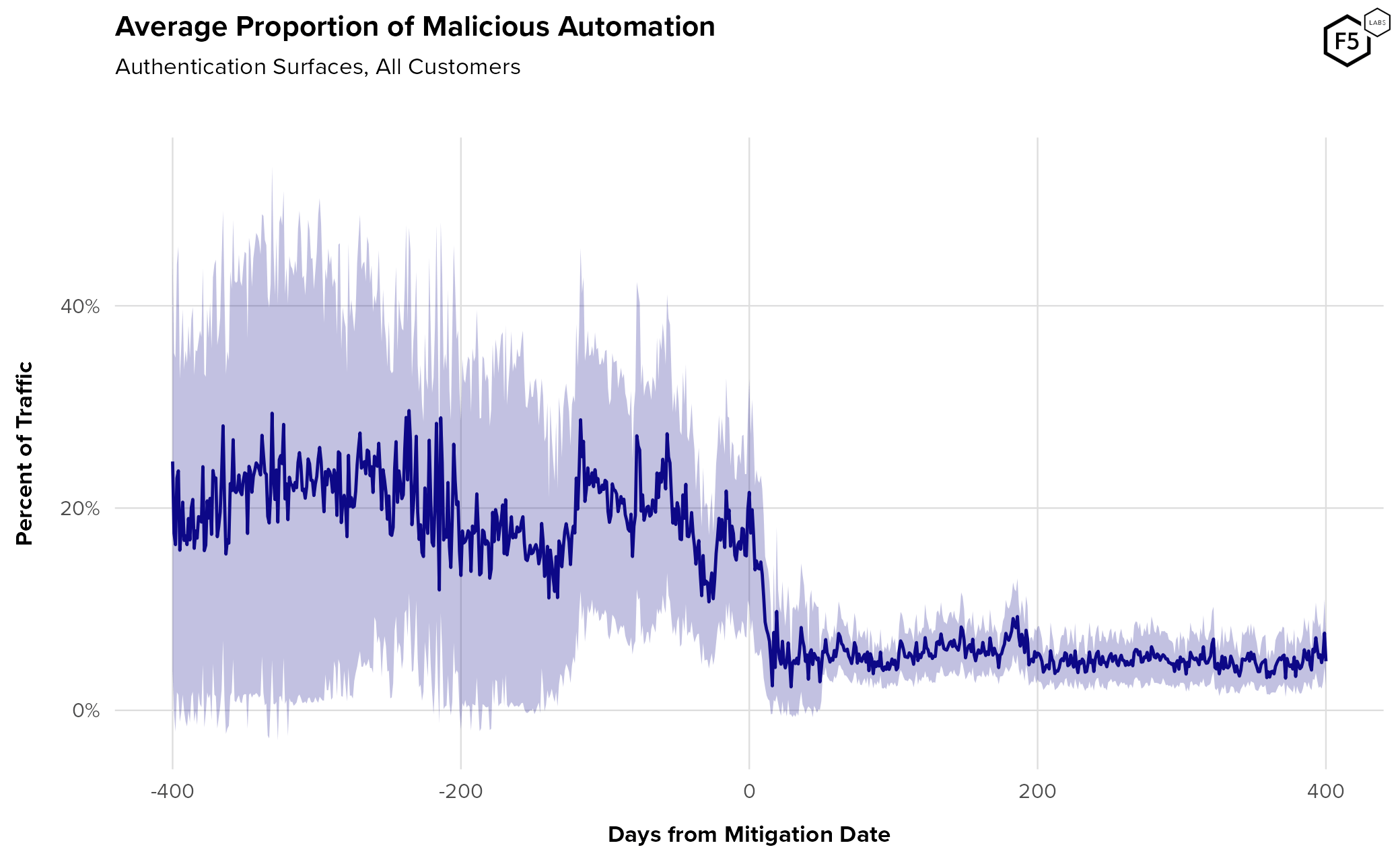
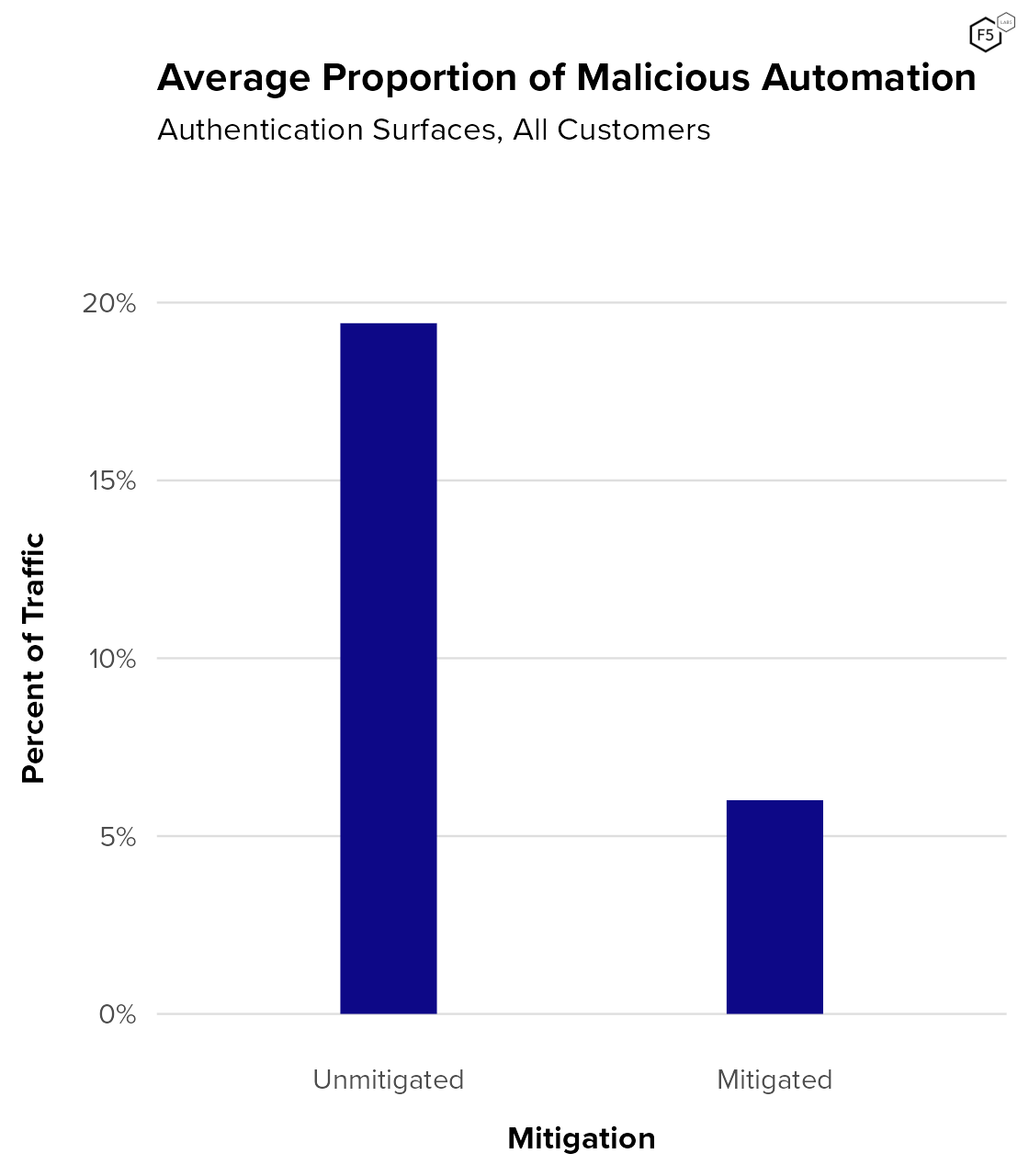
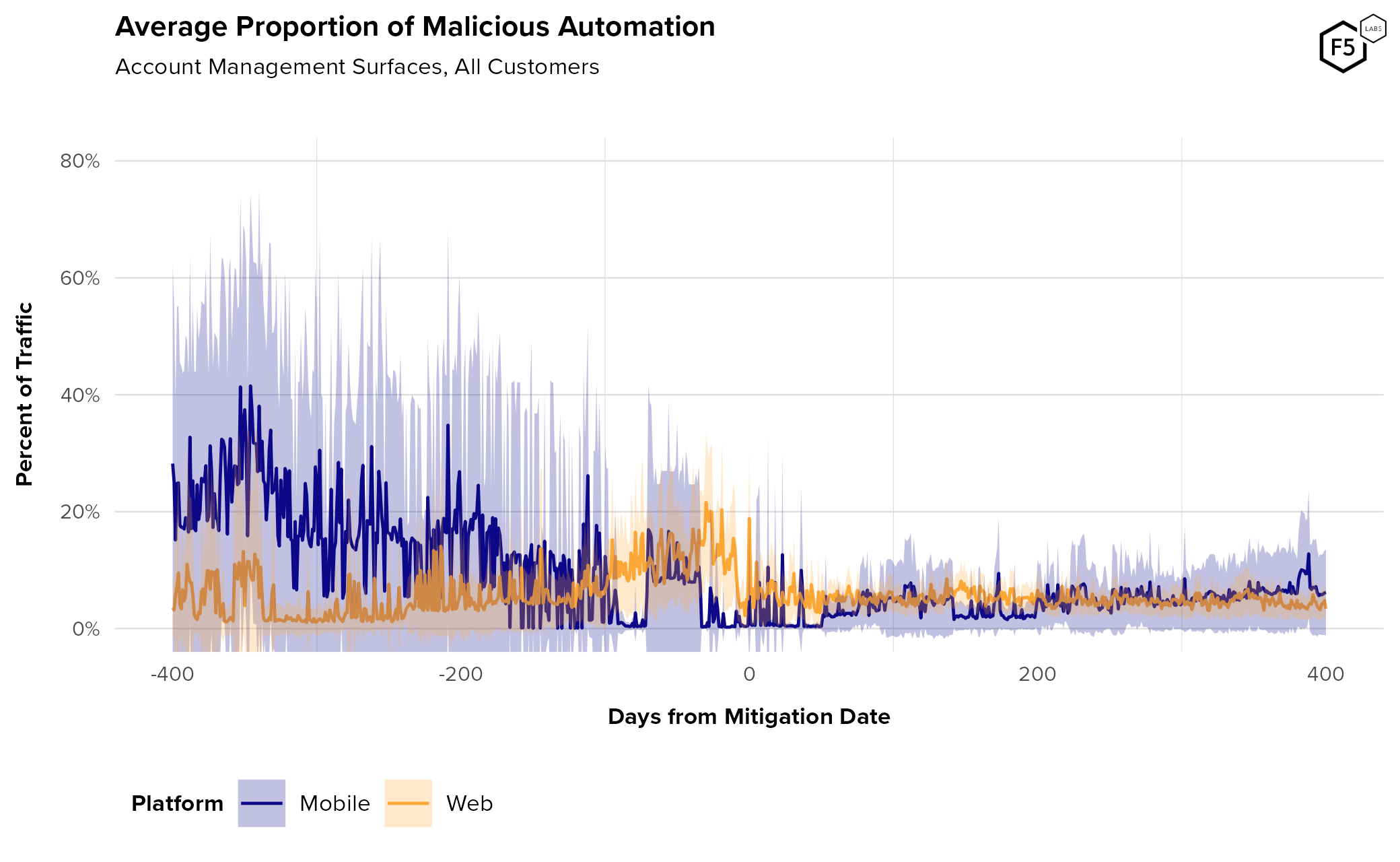
- The average proportion of credential stuffing in unmitigated traffic for sampled organizations across all sectors was 19.4%.
- Post-mitigation, the average rate of credential stuffing was 6.0%.
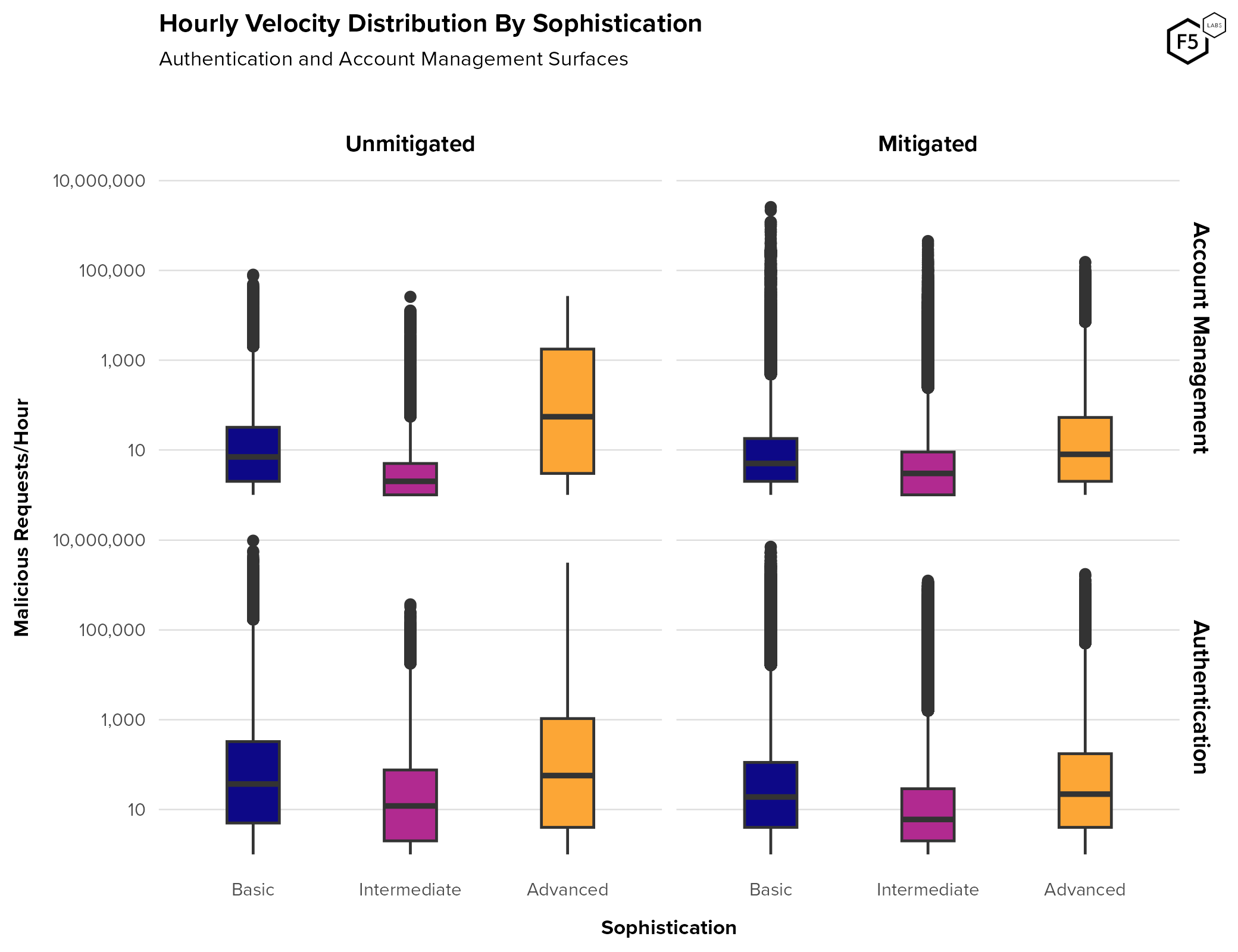
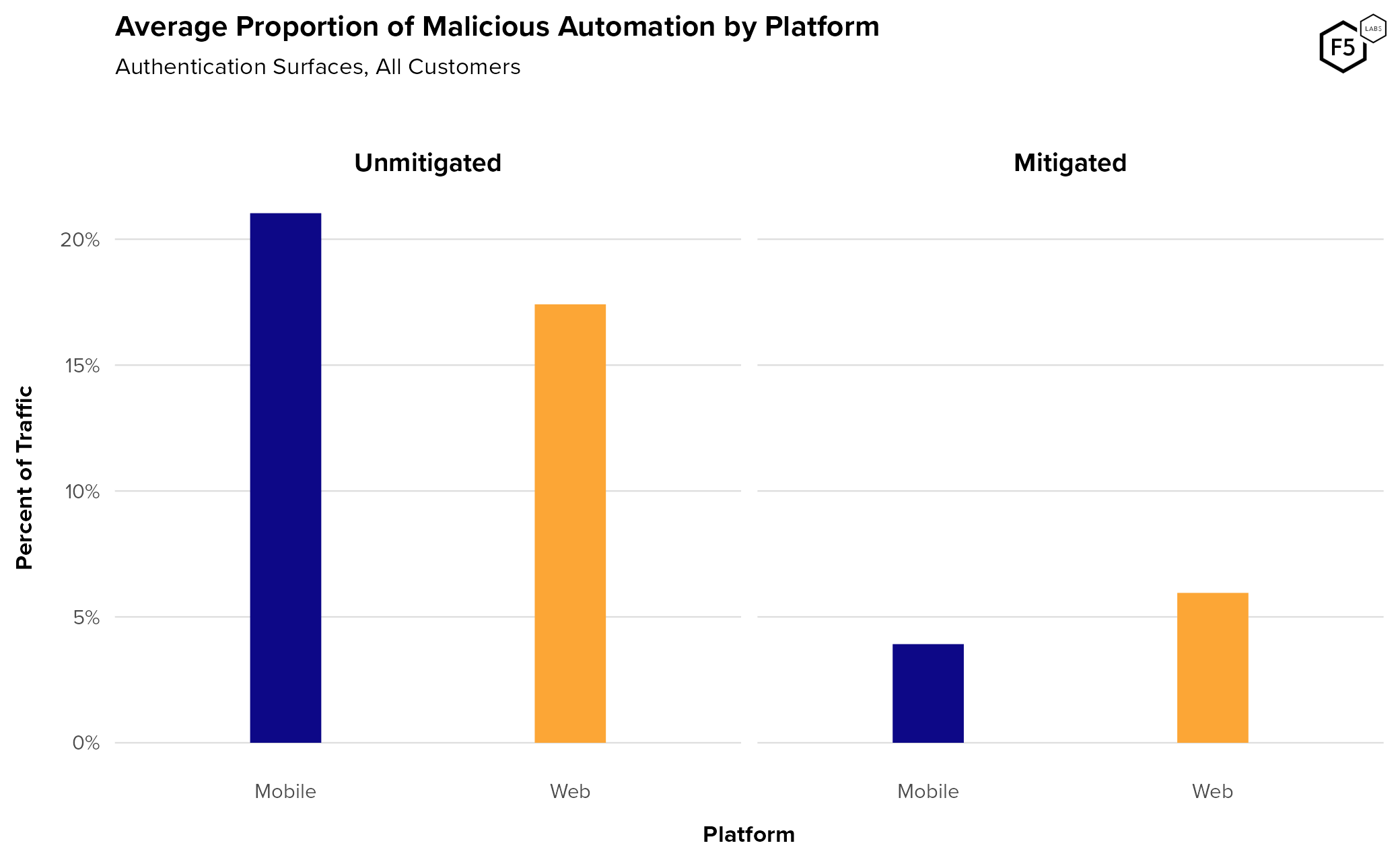
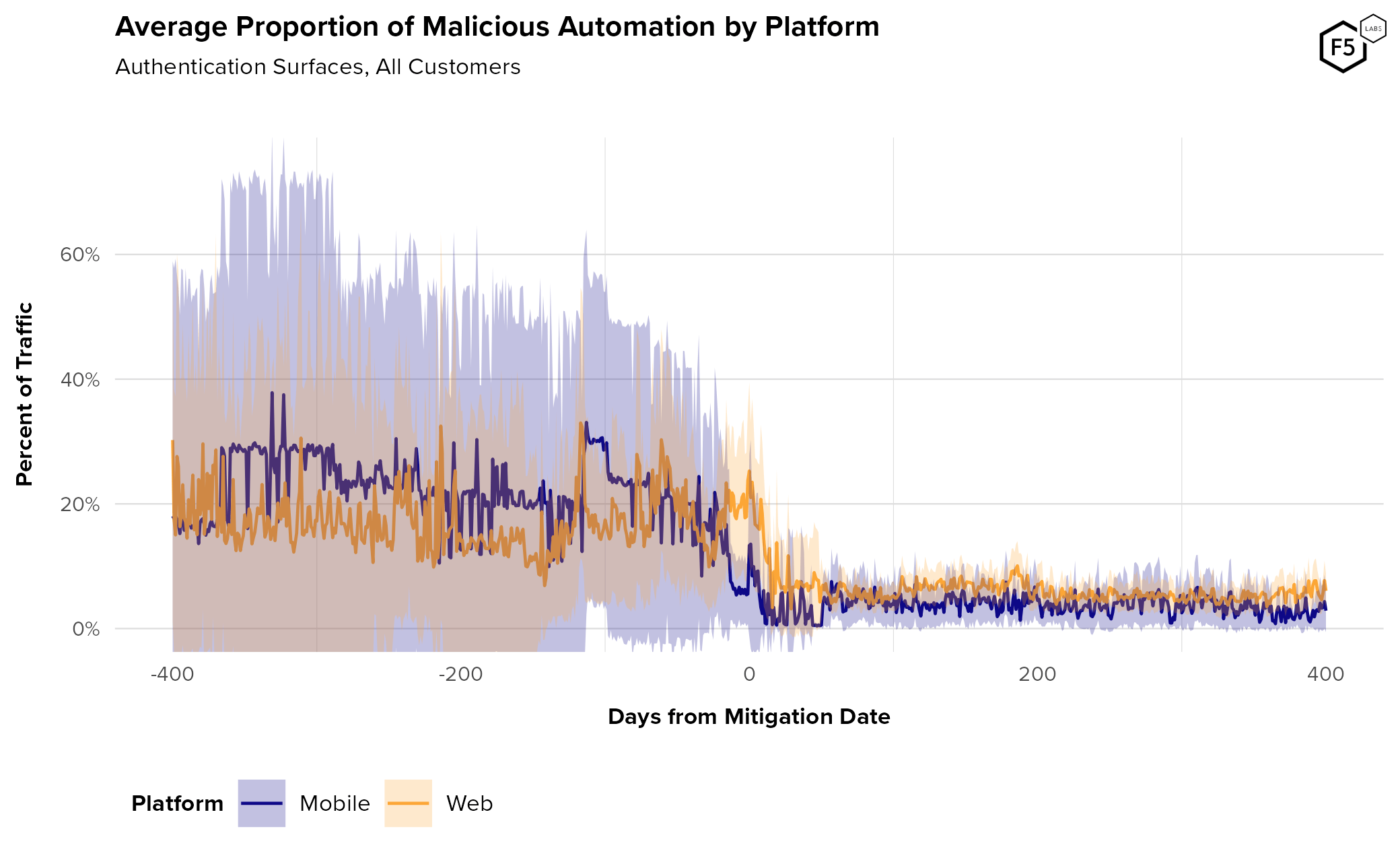
- Mobile endpoints generally see higher rates of automation pre-mitigation than web endpoints.
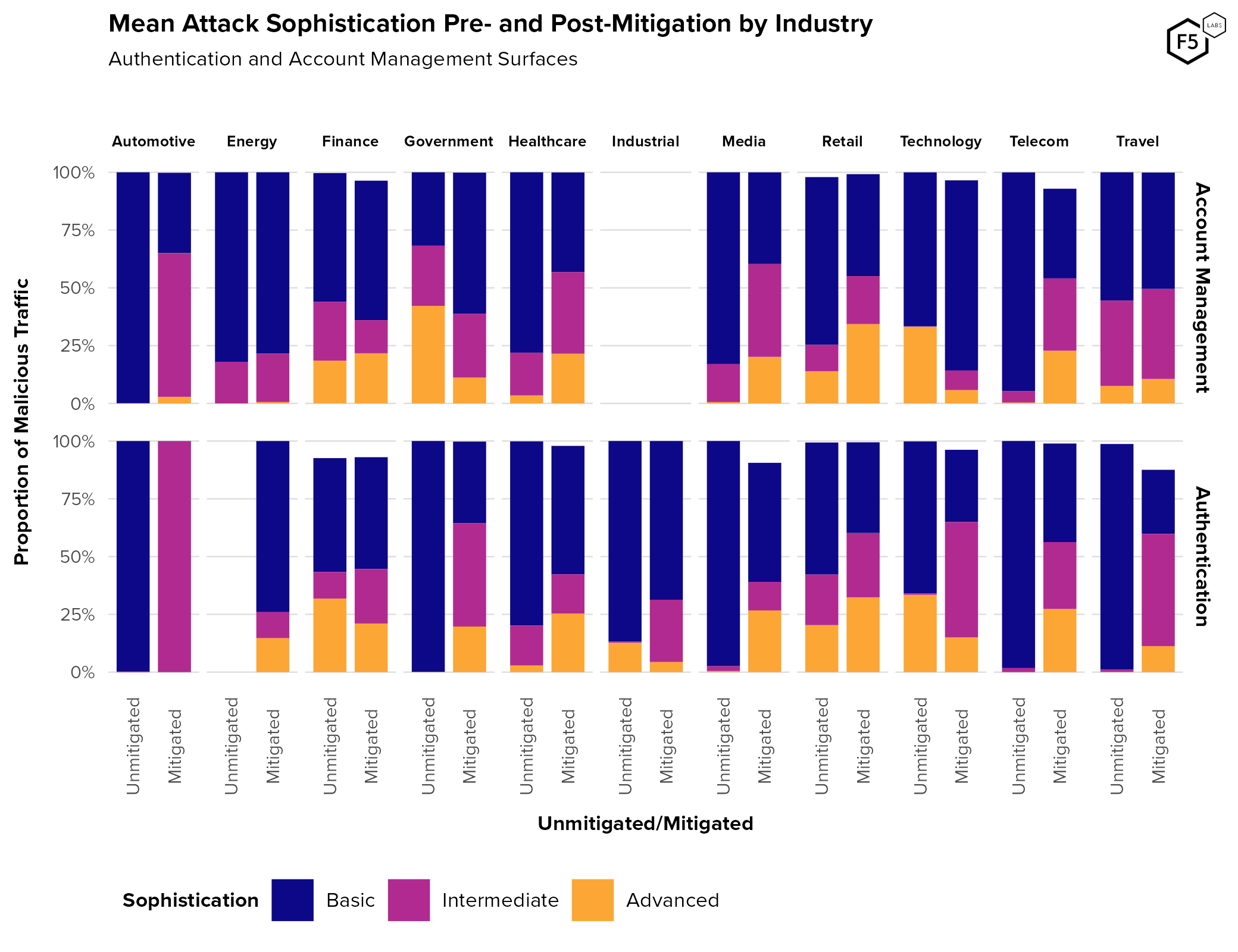
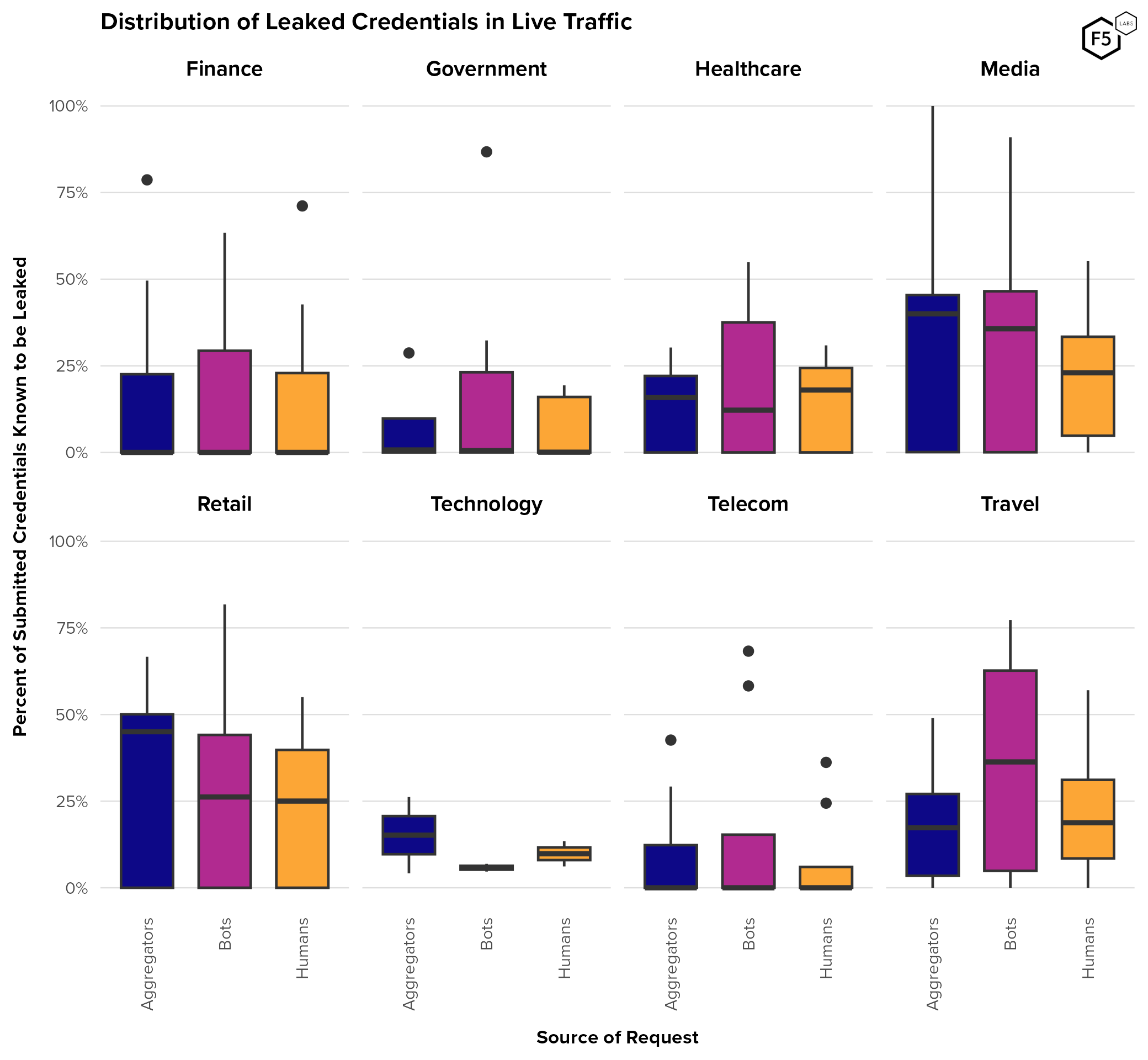
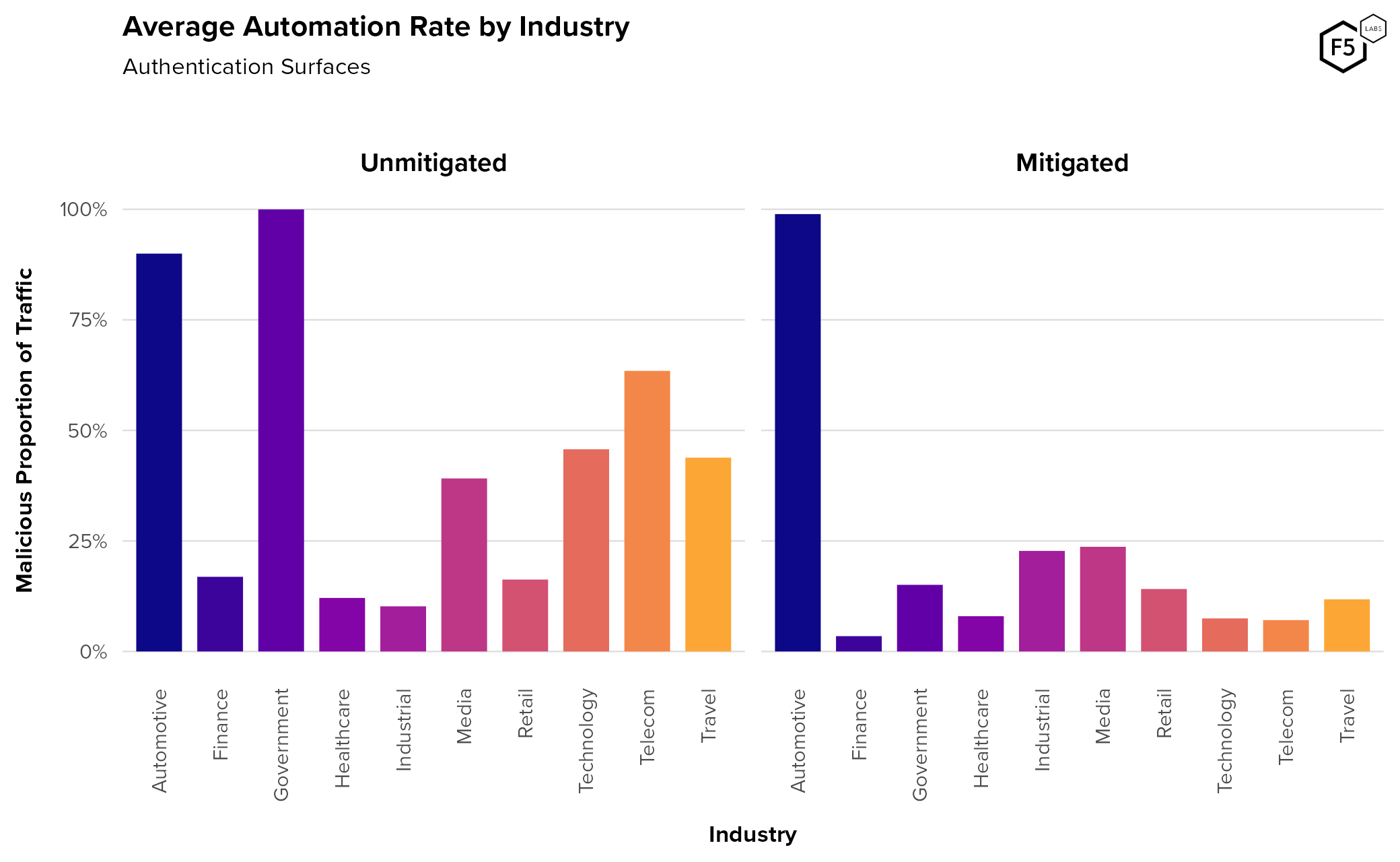
- Travel, telecommunications, and technology firms experienced higher credential stuffing rates than other sectors.
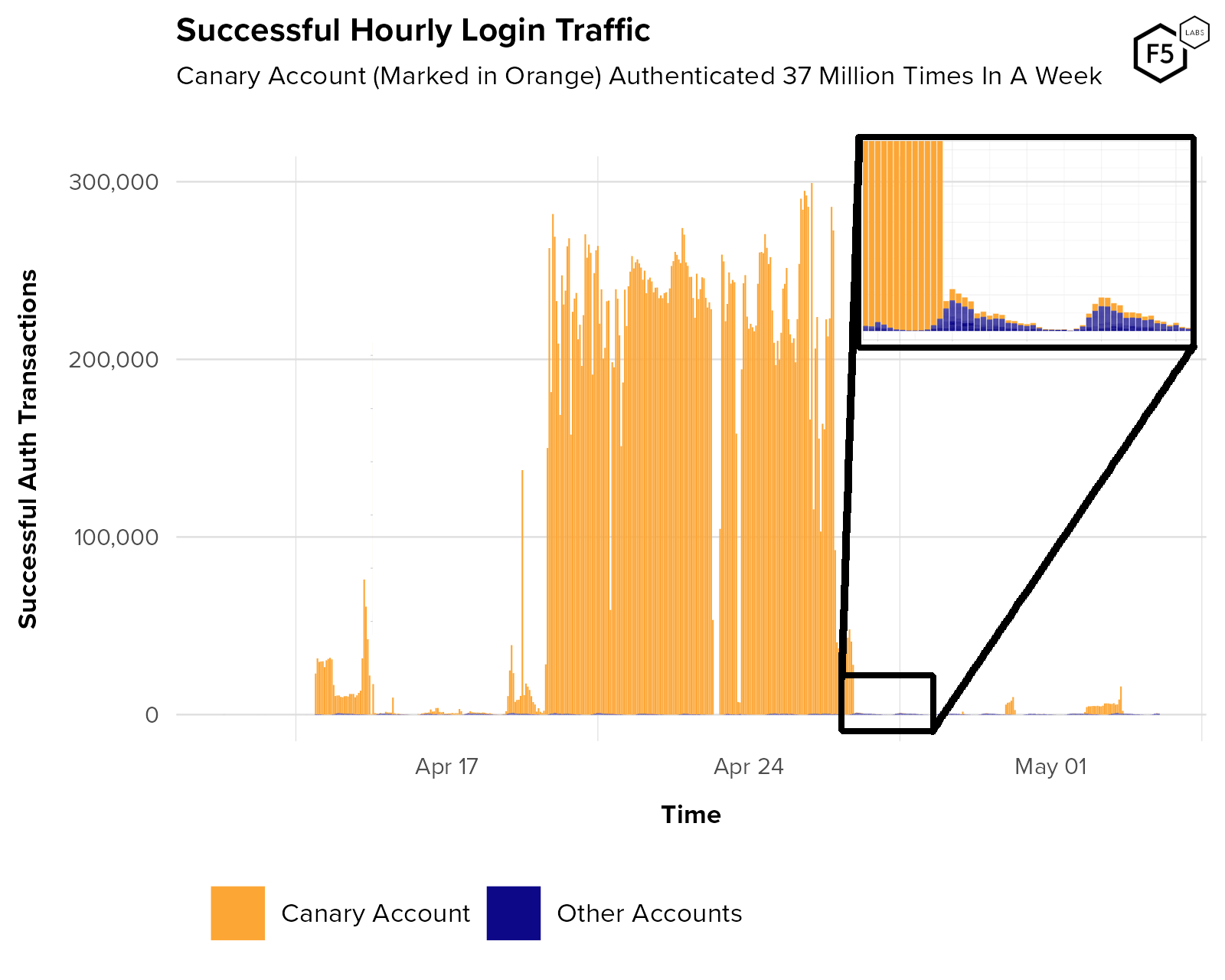
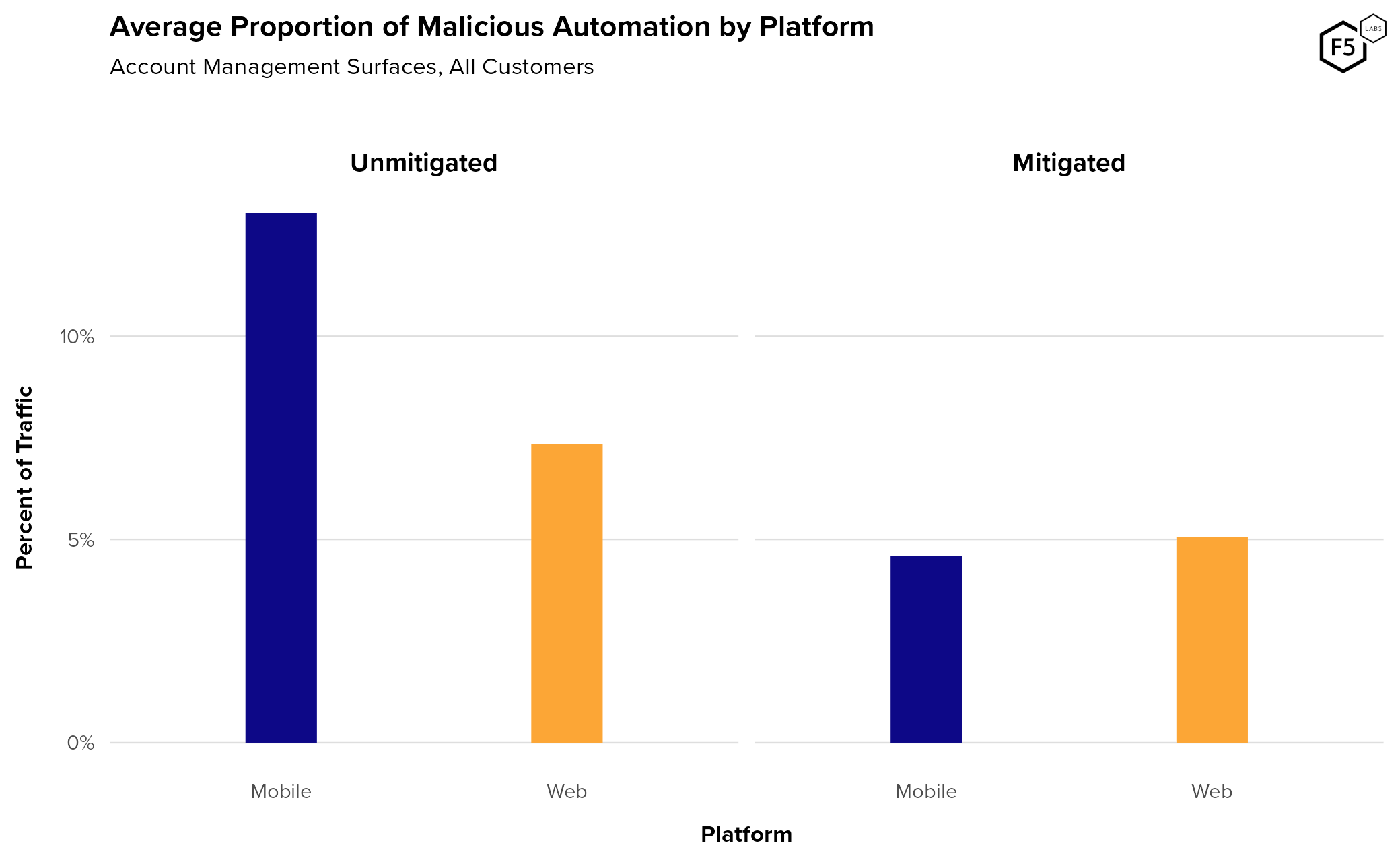
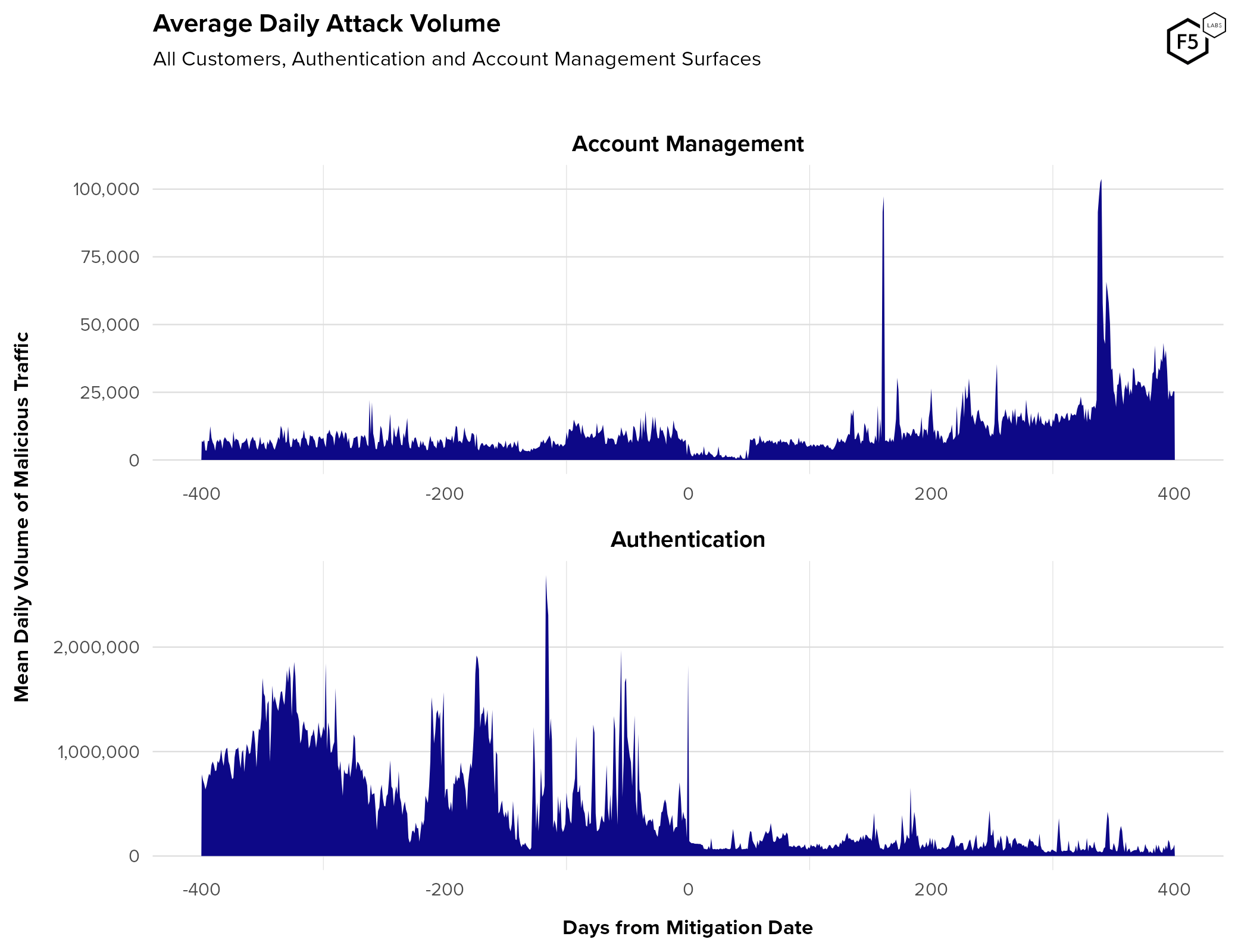
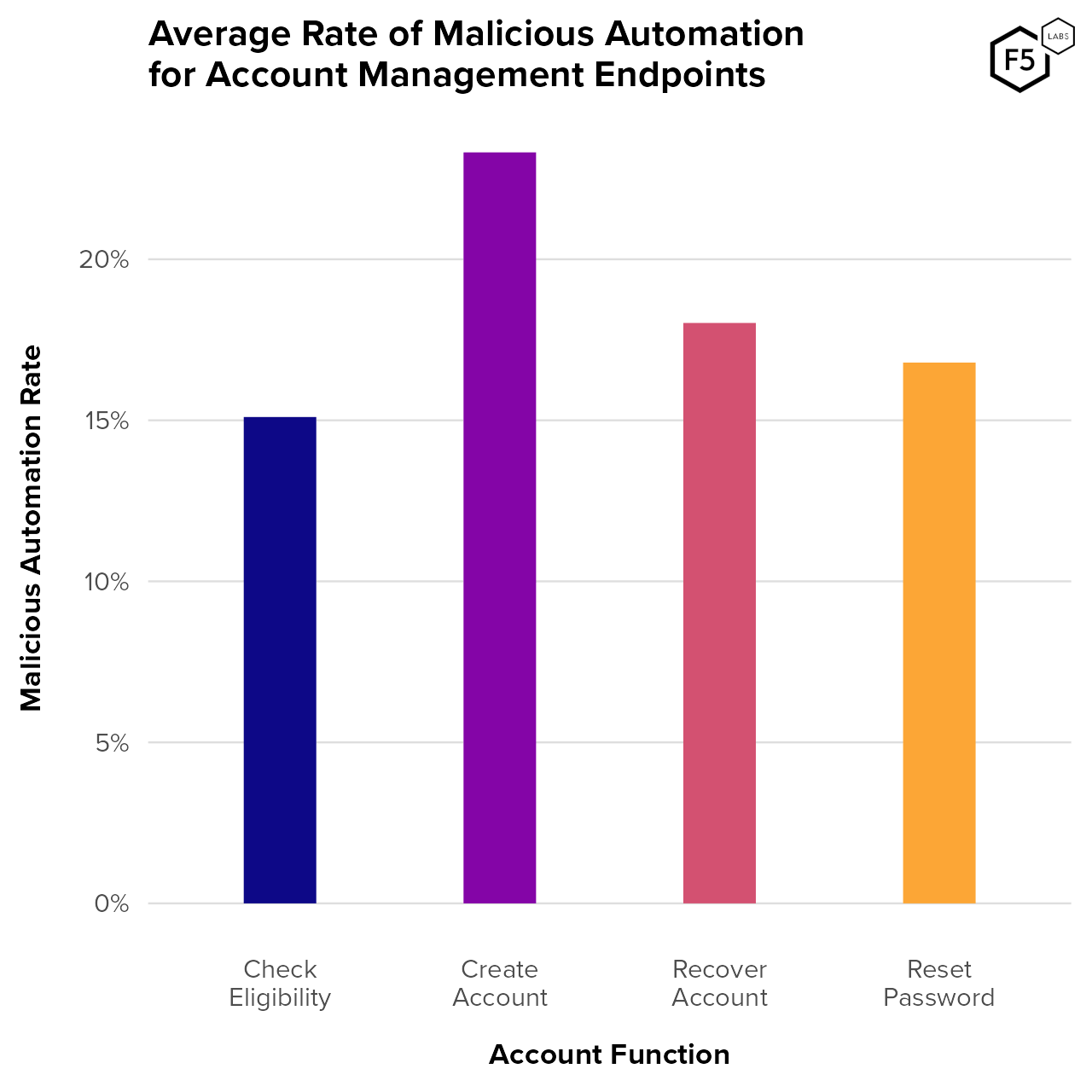
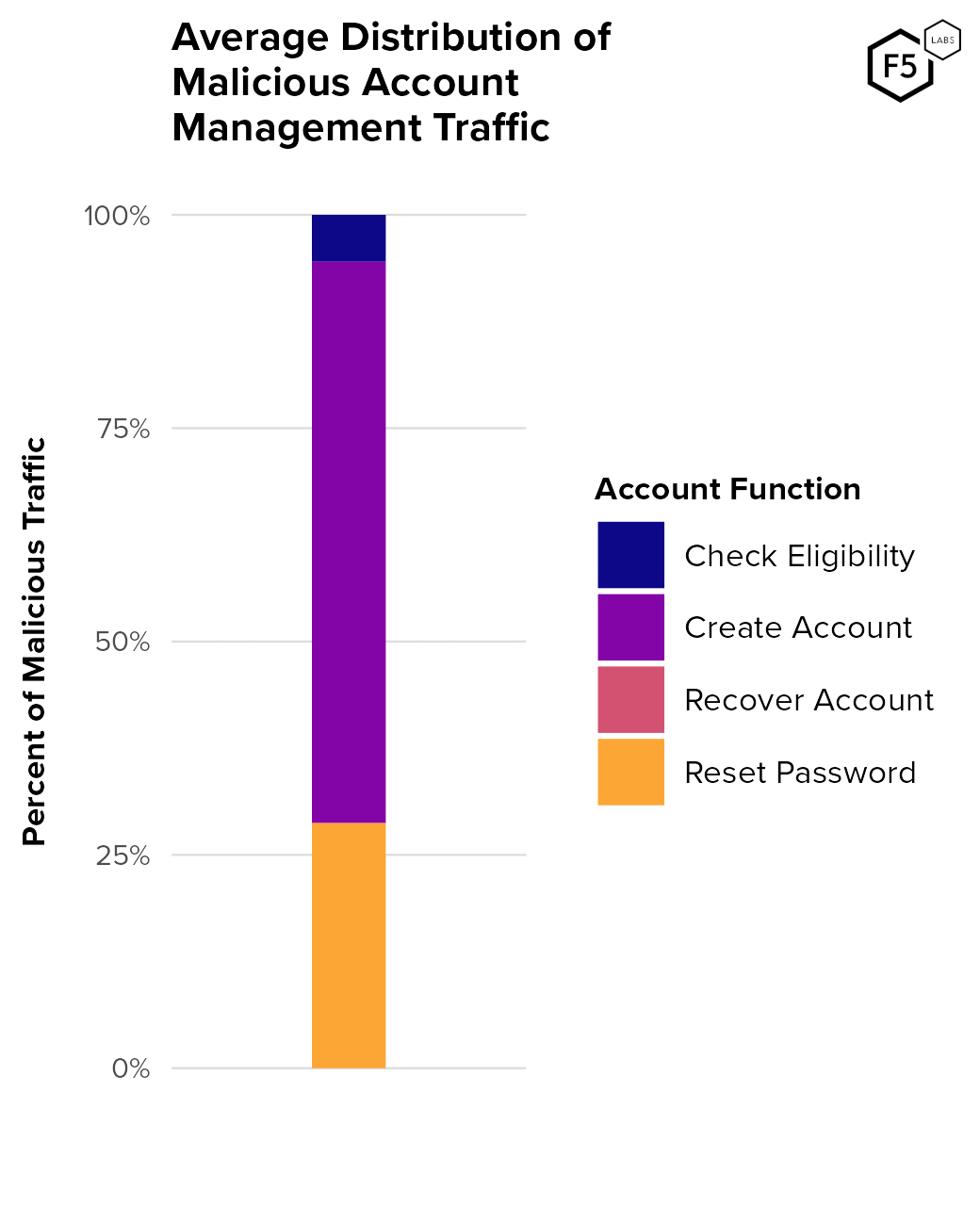
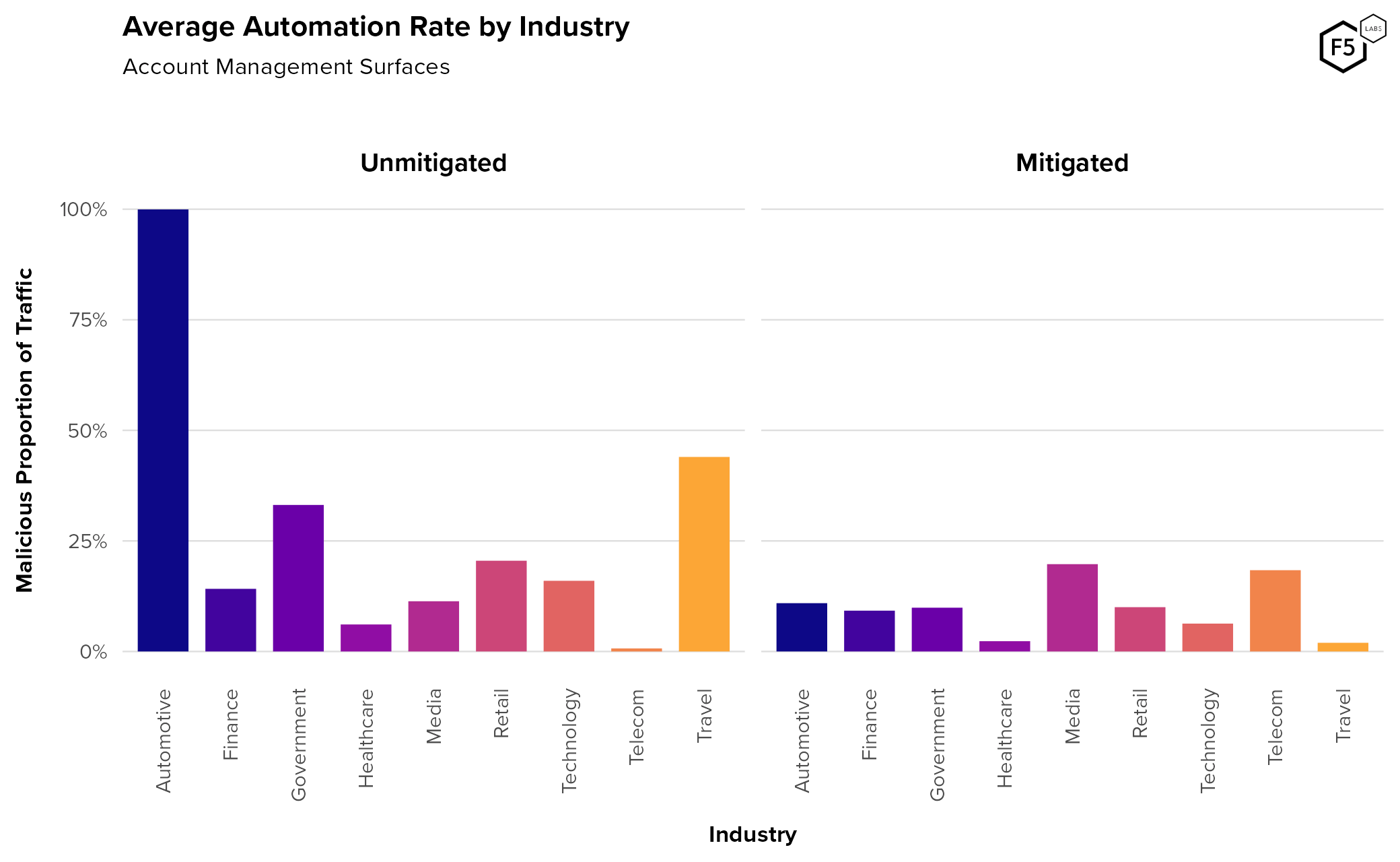
- While authentication endpoints see higher traffic and automation rates than account management endpoints, account management endpoints serve critical roles for attackers, such as the creation of canary accounts and facilitation attacks for information gain.
- 65% of credential stuffing traffic was composed of unsophisticated HTTP requests with no browser or user emulation.
- Around 20% of malicious automation traffic on authentication endpoints was sophisticated, in that it successfully emulated human behavior on a real browser, including mouse movements and keystrokes.
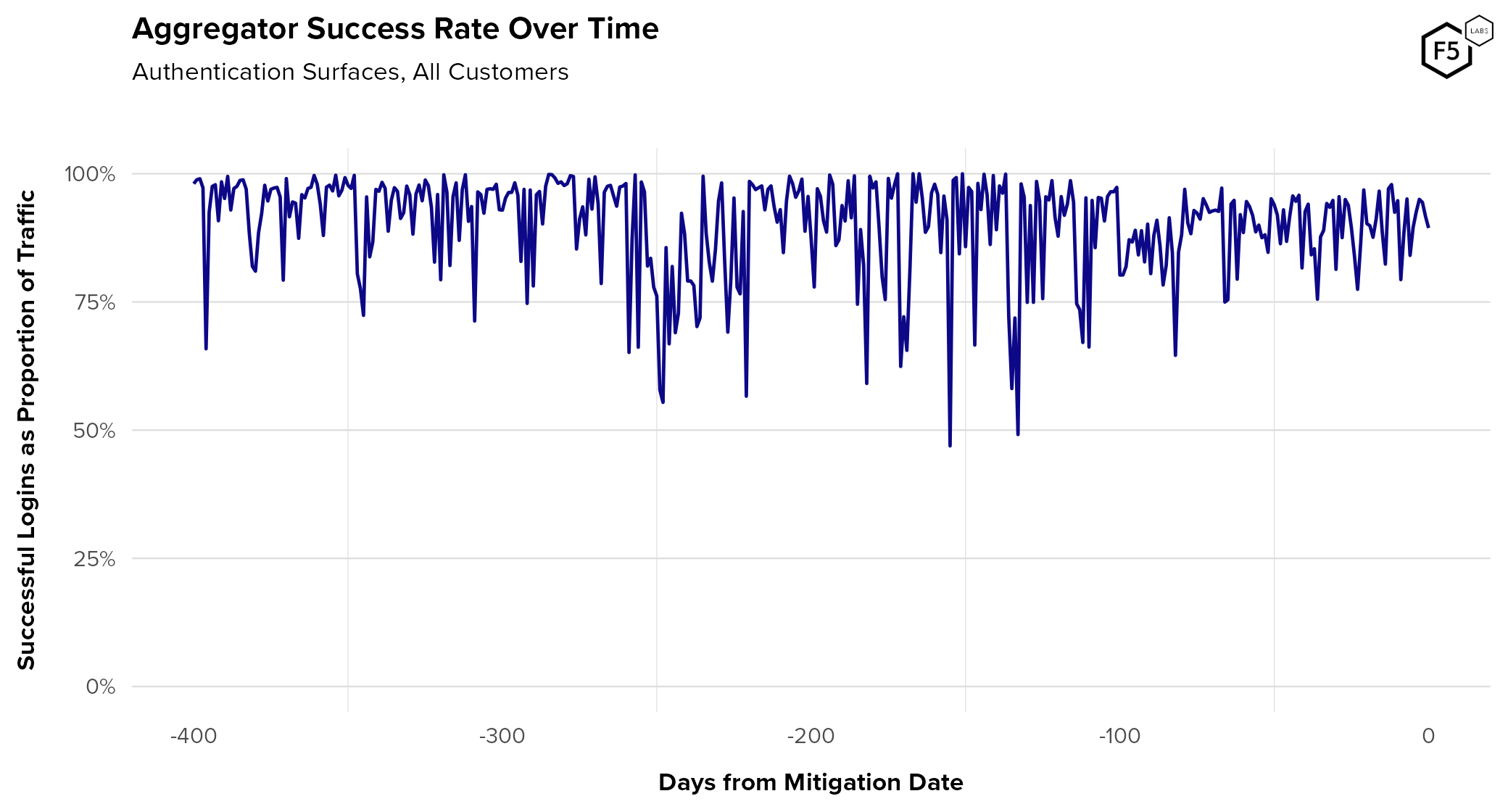
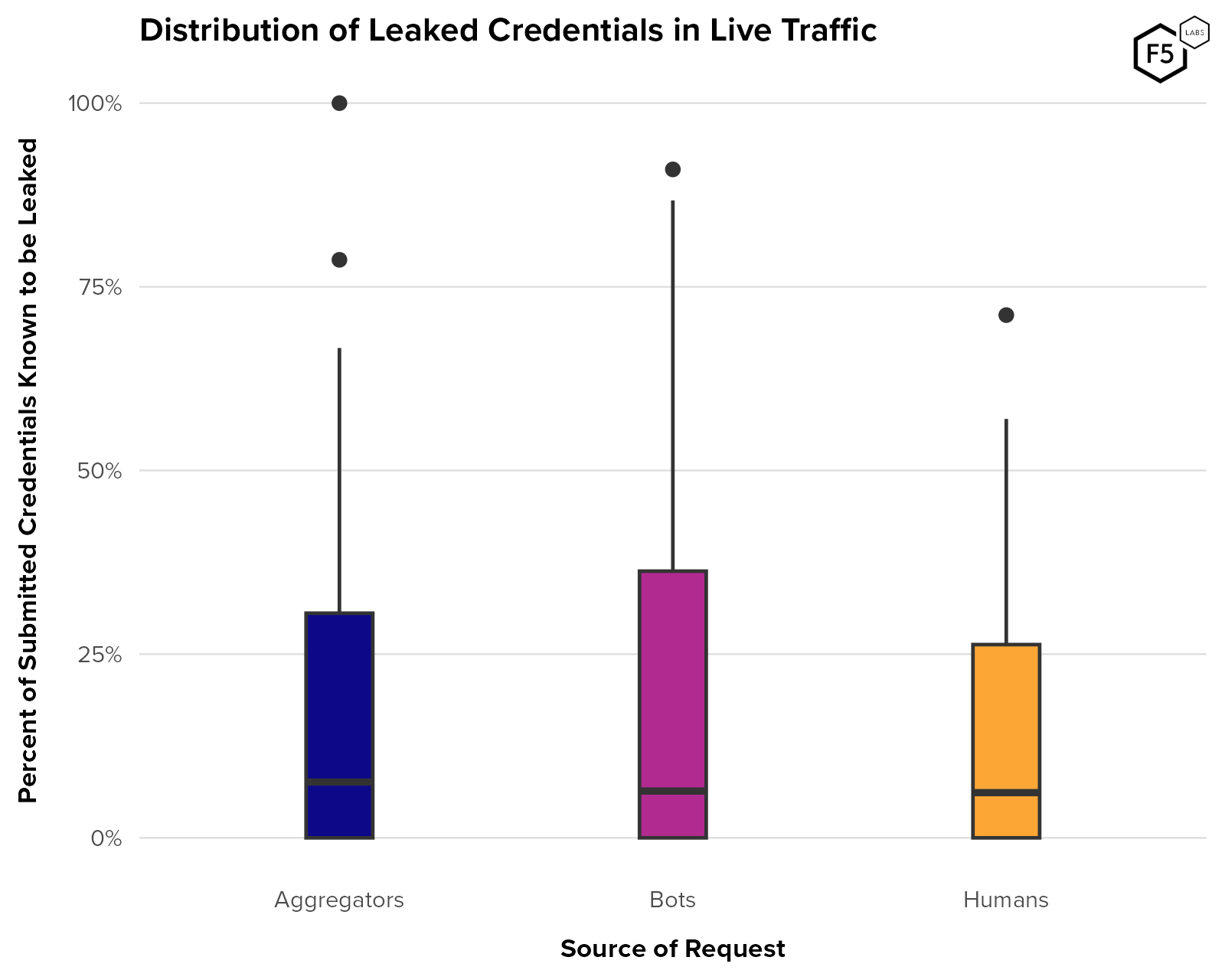
- Aggregators, which play a significant role in several industries such as finance, can be both a source of noise in terms of detecting malicious automation, as well as a vector in their own right for attackers.
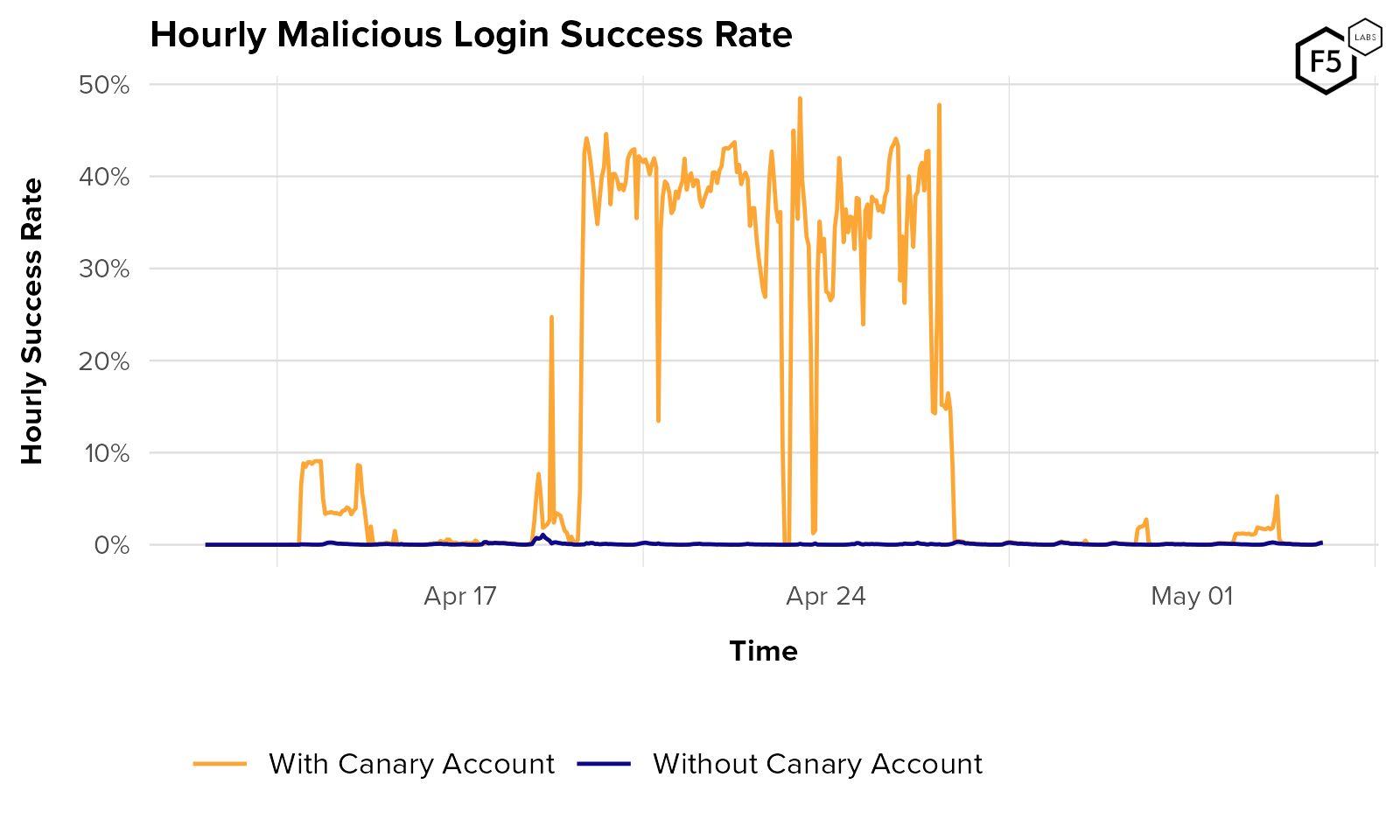
- Many organizations use authentication success rate to identify unwanted automation, but aggregator and canary account traffic can make authentication success rate metrics unreliable.
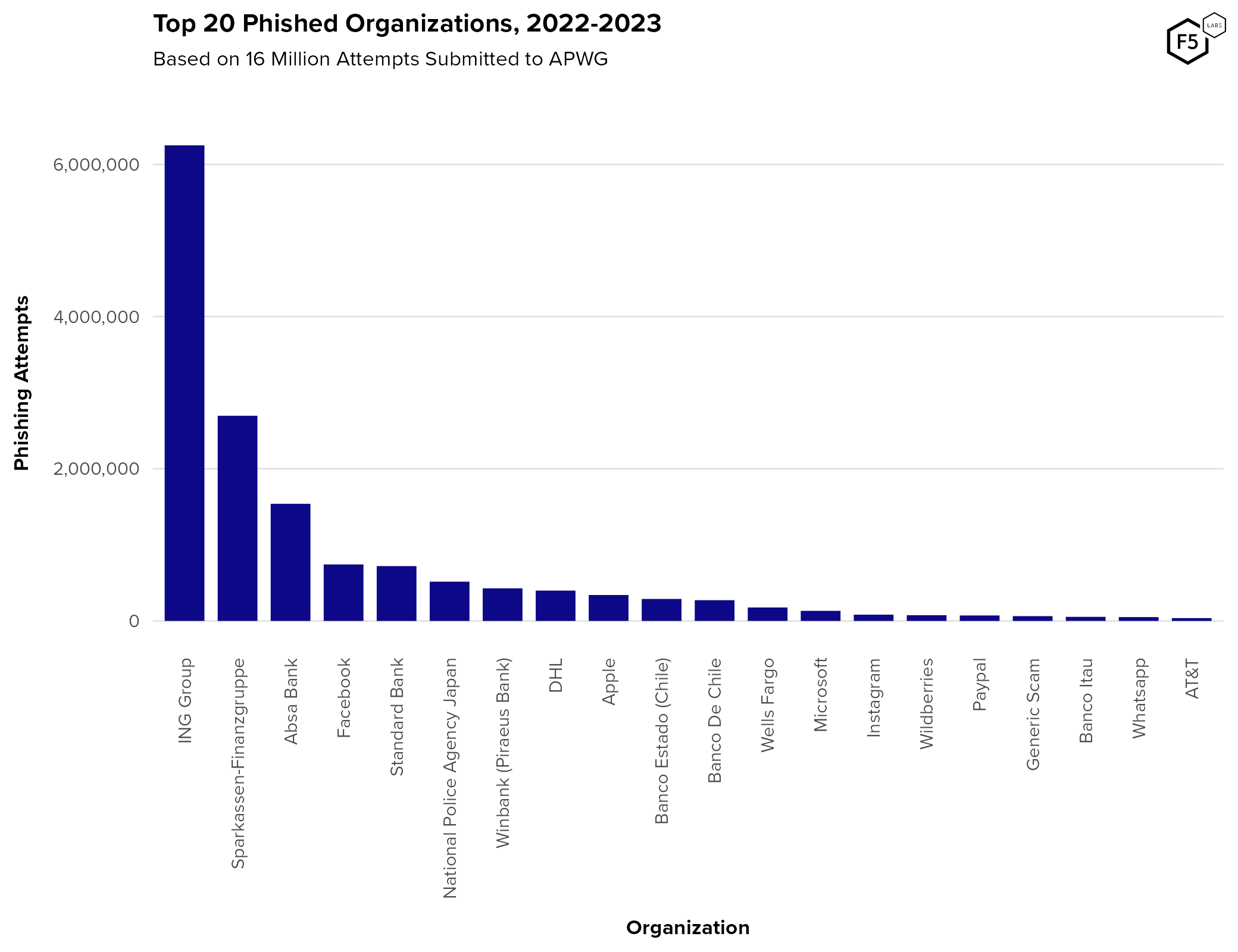
- The phishing industry has matured, with phishing kits and services driving down the requisite technical expertise and cost.
- Phishing appears to target financial organizations and large-scale/federated identity providers such as Microsoft, Facebook, Google, and Apple the most.
- Reverse phishing proxies, also known as real-time phishing proxies or man-in-the-middle (MITM) phishing, have become the standard approach. These proxies can harvest session cookies and defeat most multi-factor authentication (MFA).
- Detection evasion tools that defeat capabilities such as Google Safe Browsing are also a high priority for phishing.
- Multi-factor authentication bypass techniques have become more common, with successful strategies based on malware, phishing, and other social engineering vectors observed.
- Multi-factor authentication technologies based on public key cryptography (such as the FIDO2 suite of protocols) are significantly more resistant to observed MFA bypass techniques.
Introduction
Welcome to the 2023 Identity Threat Report. The purpose of this report is to assess and summarize the current threat landscape facing organizations as a result of the digital identities that they issue to legitimate users. In other words, we are mostly talking about credentials. Why not just call this a Credential Threat Report? The reason is because credentials are changing, and thinking about them in terms of identity instead of just a username and password situates this analysis in terms of where technology is going, not where it has been.
The growing maturity of cloud computing, with attendant shifts towards decentralized architectures and APIs, has highlighted the complexity of managing credentials in increasingly interconnected systems. It has also illuminated the importance of managing non-human entities like servers, cloud workloads, third-party services, and mobile devices. So this isn’t just a change in terminology—it is important to assess identity threats because it increasingly appears that identity is becoming a confluence of risk and attacker focus.
What’s not in the report? Well, we called this report “The Unpatchables” because digital identities represent a source of technical risk that is impossible to completely mitigate even in theory. They stand in distinction to vulnerabilities, which are binary in nature—either a system has a vulnerability to be exploited or it does not. If a system is vulnerable, we patch it (or at least we should). In contrast, we can’t patch against users. As a result, we’ll not only do our best to encapsulate various ways that attackers target identities, we’ll also try to assess how this form of threat is qualitatively different from the threat of a technical exploit.






![Figure 12. Dark web screenshot from cracked[.]to with instructions for using Burp Suite for credential stuffing.](https://www.f5.com/content/dam/f5-labs-v2/article/articles/threats/34--2023-oct-dec/20231101_identity_report/fig12.png)